 Skip to content
Skip to content 
A Year in Review: Welcome 2022 with ArangoDB.
Estimated reading time: 4 minutes
As the new year begins, It’s time to take a step back and reflect on 2021. 2021 was a big year for ArangoDB, and none of it would have been possible without the hard work and dedication of our team, as well as the continuous support from our community. This blog post recaps a few of our favorite moments from the last year and to get excited about what 2022 has in store for ArangoDB.
(more…)
A Guide to Putting Together a Virtual Conference
Estimated reading time: 7 minutes
Hello! I’m Cris Miranda, the community manager at ArangoDB, and I make sure ArangoDB has a vibrant, wholesome, and ever-growing community of amazing people. I want to share some tips and advice based on valuable lessons we’ve learned from our first-ever virtual developers’ conference.
In this short blog post, you’ll learn about how to avoid the common pitfall of ‘feature creep’ as well as gain tips on navigating virtual events platforms. I also teach you how you and your team can move together in synchronicity while keeping your goals as your guiding lighthouse. Lastly, I’ll teach you the best mindset to approach the world of rapidly changing live events. Alright, let’s get started!
(more…)
ArangoSync: A Recipe for Reliability
Estimated reading time: 18 minutes
A detailed journey into deploying a DC2DC replicated environment
When we thought about all the things we wanted to share with our users there were obviously a lot of topics to choose from. Our Enterprise feature; ArangoSync was one of the topics that we have talked about frequently and we have also seen that our customers are keen to implement this in their environments. Mostly because of the secure requirements of having an ArangoDB cluster and all of its data located in multiple locations in case of a severe outage.
This blog post will help you set up and run an ArangoDB DC2DC environment and will guide you through all the necessary steps. By following the steps described you’ll be sure to end up with a production grade deployment of two ArangoDB clusters communicating with each other with datacenter to datacenter replication.
All of the best practices that we use during our day-to-day operations regarding encryption and secure authentication have been used while writing this blog post and every step in the setup will be explained in detail, so there will be no need to doubt, research or ponder about which options to use and implement in any situation; Your home lab, your production grade database environment and basically anywhere you want to run a deployment like this.
A note of importance however is that the ArangoSync feature including the used encryption at rest are Enterprise features that we don’t offer in our Community version of ArangoDB. If you don’t have an available Enterprise license for this project, you can download an evaluation version that has all functionality at: https://www.arangodb.com/download-arangodb-enterprise/
That's a lot of words as an introduction but what actually is ArangoSync?
ArangoSync is our Enterprise feature that enables you to seamlessly and asynchronously replicate the entire structure and content in an ArangoDB cluster in one location to a cluster in another location. Imagine different cloud provider regions or different office locations in your company.
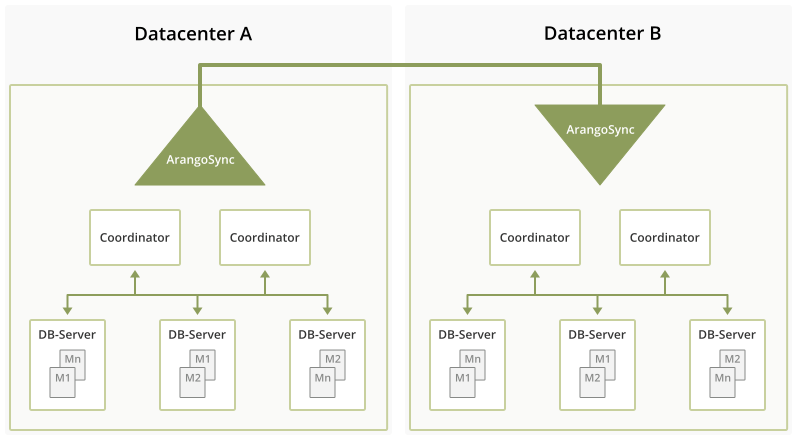
To run successfully, ArangoSync needs two fully functioning clusters and will not be useful when you’re only running a single instance of ArangoDB. So please also consider this when you’re making any plans to change or implement your database architecture.
In the above explanation I mentioned that ArangoSync works asynchronously. What this basically means is that when a client processes and writes data into the source datacenter, it will consider the request to be complete and finished before the data has been replicated to the other datacenter. The time needed to completely replicate changes to the other datacenter is typically in the order of seconds, but this can vary significantly depending on load, network & computer capacity, so be mindful of what hardware you choose so it will have a positive and useful impact on your environment in terms of performance and suits your use case.
ArangoSync performs replication in a single direction only. That means that you can replicate data from cluster A to cluster B or from cluster B to cluster A, but never to and from both at the same time.
ArangoSync runs a completely autonomous distributed system of synchronisation workers. Once configured properly via this blog post or any related documentation, it is designed to run continuously without manual intervention from anyone.
This of course doesn’t mean that it doesn’t require any maintenance at all and as with any distributed system some attention is needed to monitor its operation and keep it secure (Think of certificate & password rotation just to name two examples).
Once configured, ArangoSync will replicate both the structure and data of an entire cluster. This means that there is no need to make additional configuration changes when adding/removing databases or collections. Any data or metadata in the cluster will be automatically replicated.
When to use it… and when not to use it
ArangoSync is a good solution in all cases where you want to replicate data from one cluster to another without the requirement that the data is available immediately in the other cluster.
If you’re still doubting whether ArangoSync is the option for you then review the following list of no’s and if they apply to you or your organization.
- You want to use bidirectional replication data from cluster A to cluster B and vice versa.
- You need synchronous replication between 2 clusters.
- There is no network connection between cluster A and B.
- You want complete control over which database, collection & documents are replicated and which ones will not be.
Okay I’m done reading the official part, now let's get started!
To start off with the first ArangoDB cluster, you will need at least 3 nodes. In this blog post, we’re of course using 6 nodes for both data centers, meaning 3 nodes per datacenter.
As an example we’re using the hypothetical locations dc1 and dc2 which can be located anywhere in the world but also in your test environment living in multiple VMs;
sync-dc1-node01
sync-dc1-node02
sync-dc1-node03
sync-dc2-node01
sync-dc2-node02
sync-dc2-node03The three nodes with “dc1” are located in the first datacenter, the three nodes with “dc2” are located in the second datacenter. To test the location can of course be any local environment that supports running six nodes at once with sufficient resources.
In this blog post, we picked Ubuntu Linux as the OS but as we’re using the .tar.gz distribution with static executables, this means that you can choose whatever Linux distribution your organization runs and that you’re comfortable with. To control the ArangoDB installation, we use systemd, so the distribution should support systemd or you have to change things for automatic restarts after a reboot.
Currently, the most recent release of ArangoDB is version 3.8.0, so all of our examples mentioning file names will be using the arangodb3e-linux-3.8.0.tar.gz binary and the following ports need to be open/accessible on each node;
- 8528 : starter
- 8529 : coordinator
- 8530 : dbserver
- 8531 : agent
- 8532 : syncmaster
- 8533 : syncworkerObviously, the process name next to the port name is for illustration purposes so you know what port belongs to which process.
We will roll out the clusters as the root user, but this is of course not necessary. In fact, our own packages create the arangodb user with the installation. It is considered good practice to keep file ownerships separate for services and should be done so in production environments. We could have used any normal user account, provided we have access to the nodes and their filesystem.
The only significant part where we need root access is to set up the systemd service. Another important prerequisite is that you have properly configured SSH access to all nodes.
Setting up ArangoDB clusters - A detailed overview
We will go through all of the detailed next steps. There are a bunch of them to follow so grab a cup of coffee or tea and sit back to work on this. As you might notice, the second half of the steps are repetitive as we’re setting up two similar clusters so we did not make a mistake to make you think you’ve misread. The settings for both clusters slightly differ from each other and therefore we need to separate the installation steps. All commands you need to follow are explained and written out in detail and can even be copied and pasted for your own future reference when you’d like to automate the installation steps in your own environment.
Extract the downloaded binary in its target location:
Assuming the archive file arangodb3e-linux-3.8.0.tar.gz is present on your local machine, we deploy it to each node in the first cluster with the following commands:
scp arangodb3e-linux-3.8.0.tar.gz root@sync-dc1-node01:/tmp
scp arangodb3e-linux-3.8.0.tar.gz root@sync-dc1-node02:/tmp
scp arangodb3e-linux-3.8.0.tar.gz root@sync-dc1-node03:/tmpTo install ArangoDB, we run the following command on all cluster nodes:
mkdir -p /arangodb/data
cd /arangodb
tar xzvf /tmp/arangodb3e-linux-3.8.0.tar.gz
export PATH=/arangodb/arangodb3e-linux-3.8.0/bin:$PATHA quick check to test the installation for functionality:
cd /arangodb
mkdir data
cd data
arangodb --starter.mode=singleThis will launch a single server on each machine on port 8529, without any authentication, encryption, or anything. You can point your browser to the nodes on port 8529 to verify that the firewall settings are correct. If this does not work and you cannot reach the UI of the database, you should stop here and debug your firewall otherwise, you are bound to run into more difficult trouble later on, for example, because the processes in your cluster cannot reach each other over the network.
Afterward, simply press Control-C and run the following to clean up:
cd /arangodb/data
rm -rf *Having tested basic functionality, let's get to the actual deployment of the cluster;
Create a shared secret for the first cluster
The different processes in the ArangoDB cluster must authenticate themselves against each other. To this end, we require a shared secret, which is deployed to each cluster machine. Here is a simple way to create such a secret on your laptop and to deploy it to each of the cluster nodes:
arangodb create jwt-secret
scp secret.jwt root@sync-dc1-node01:/arangodb/data
scp secret.jwt root@sync-dc1-node02:/arangodb/data
scp secret.jwt root@sync-dc1-node03:/arangodb/dataNote that we are using the arangodb executable from the distribution to create a secret file secret.jwt. For this to work, you have to install ArangoDB on your laptop, too. If you want to avoid this, you can simply create all the secrets and keys on one of your cluster nodes and use arangodb there.
Please keep the file secret.jwt in a safe place, possession of the file grants unrestricted superuser access to the database.
Create a CA and server keys, Then deploy them:
All communications to the database as well as all communications within an ArangoDB cluster need to be encrypted via TLS. To this end, every process needs to have a pair of a private key and a corresponding public key (aka server certificate). During the steps of this blog post, we will create a self-signed CA key pair (the public CA key is signed by its own private key) and use that as the root certificate.
We use the following commands to create the CA keys tls-ca.key (private) and tls-ca.crt (public) as well as the server key and certificate in the keyfile files. A keyfile contains the private server key as well as the full chain of public certificates. Note how we add the server names into the server certificates:
arangodb create tls ca
arangodb create tls keyfile --host localhost --host 127.0.0.1 --host sync-dc1-node01 --host sync-dc1-node02 --host sync-dc1-node03 --keyfile sync-dc1-nodes.keyfile
scp sync-dc1-nodes.keyfile root@sync-dc1-node01:/arangodb/data
scp sync-dc1-nodes.keyfile root@sync-dc1-node02:/arangodb/data
scp sync-dc1-nodes.keyfile root@sync-dc1-node03:/arangodb/dataThese commands are all executed on your local machine and deploy the server key to the cluster nodes. Keep the tls-ca.key file secure, it can be used to sign certificates, in particular, do not deploy it to your cluster! Furthermore, keep the sync-dc1-node*.keyfile files secure, since possession of them allows you to listen in to the communication with your servers.
Create an encryption key for encryption at rest:
ArangoDB can keep all the data on disk encrypted using the AES-256 encryption standard. This is a requirement for most secure database installations. To this end, we need a 32 byte key for the encryption. It can basically consist of random bytes. Use these commands to set up an encryption key:
dd if=/dev/random of=sync-dc1-nodes.encryption bs=1 count=32
chmod 600 sync-dc1-nodes.encryption
scp sync-dc1-nodes.encryption root@sync-dc1-node01:/arangodb/data
scp sync-dc1-nodes.encryption root@sync-dc1-node02:/arangodb/data
scp sync-dc1-nodes.encryption root@sync-dc1-node03:/arangodb/dataKeep the encryption key secret, because possession allows one to open a database at rest, if one can get hold of the database files in the filesystem.
Create a shared secret to use with ArangoSync:
The data center to data center replication in ArangoDB is implemented as a set of external processes. This allows for scalability and minimal impact on the actual database operations. The executable for the ArangoSync system is called arangosync and is packaged with our Enterprise Edition. Similar to the above steps, we need to create a shared secret for the different ArangoSync processes, such that they can authenticate themselves against each other.
We produce the shared secret in a way that is very similar to the one for the actual ArangoDB cluster:
arangodb create jwt-secret --secret syncsecret.jwt
scp syncsecret.jwt root@sync-dc1-node01:/arangodb/data
scp syncsecret.jwt root@sync-dc1-node02:/arangodb/data
scp syncsecret.jwt root@sync-dc1-node03:/arangodb/dataKeep the file syncsecret.jwt a secret, since its possession allows you to interfere with the ArangoSync system.
Create a TLS encryption setup for ArangoSync:
The same arguments about encrypted traffic and man-in-the-middle attacks apply to the ArangoSync system as explained above for the actual ArangoDB cluster. We choose to reuse the same CA key pair as above for the TLS certificate and key setup. For a change, we work with the same server keyfile for all three nodes.
Here we create the server keyfile, signed by the same CA key pair in tls-ca.key and tls-ca.crt:
arangodb create tls keyfile --host localhost --host 127.0.0.1 --host sync-dc1-node01 --host sync-dc1-node02 --host sync-dc1-node03 --keyfile synctls.keyfile
scp synctls.keyfile root@sync-dc1-node01:/arangodb/data
scp synctls.keyfile root@sync-dc1-node02:/arangodb/data
scp synctls.keyfile root@sync-dc1-node03:/arangodb/dataAs usual, keep the file synctls.keyfile secure, since its possession allows it to listen to the encrypted traffic with the ArangoSync system.
Set up client authentication setup for ArangoSync:
There is one more secretive thing to set up before we can hit the launch button. The two ArangoSync systems in the two data centers need to authenticate each other. Actually, the second data center (“DC B”, the replica), needs to authenticate itself with the first data center (“DC A”, the original). Since this is cross data center traffic, the authentication is done via TLS client certificates.
We create and deploy the necessary files with the following commands on your local machine:
arangodb create client-auth ca
arangodb create client-auth keyfile
scp client-auth-ca.crt root@sync-dc1-node01:/arangodb/data
scp client-auth-ca.crt root@sync-dc1-node02:/arangodb/data
scp client-auth-ca.crt root@sync-dc1-node03:/arangodb/dataKeep the file client-auth-ca.key secret, since it allows signing additional client authentication certificates. Do not store this on any of the cluster nodes.
Also, keep the file client-auth.keyfile secret, since it allows authentication with a syncmaster in either data center.
The first cluster can now be launched:
We launch the whole system by means of the ArangoDB starter, which is included in the ArangoDB distribution. We launch the starter via a systemd service file, which looks basically like the following snippet but feel free to adapt it to your needs:
[Unit]
Description=Run the ArangoDB Starter
After=network.target
[Service]
# system limits
LimitNOFILE=131072
LimitNPROC=131072
TasksMax=131072
Restart=on-failure
KillMode=process
Environment=SERVER=sync-dc1-node01
ExecStart=/arangodb/arangodb3e-linux-3.8.0/bin/arangodb \
--starter.data-dir=/arangodb/data \
--starter.address=${SERVER} \
--starter.join=sync-dc1-node01,sync-dc1-node02,sync-dc1-node03 \
--auth.jwt-secret=/arangodb/data/secret.jwt \
--ssl.keyfile=/arangodb/data/sync-dc1-nodes.keyfile \
--rocksdb.encryption-keyfile=/arangodb/data/sync-dc1-nodes.encryption \
--starter.sync=true \
--sync.start-master=true \
--sync.start-worker=true \
--sync.master.jwt-secret=/arangodb/data/syncsecret.jwt \
--sync.server.keyfile=/arangodb/data/synctls.keyfile \
--sync.server.client-cafile=/arangodb/data/client-auth-ca.crt \
TimeoutStopSec=60
[Install]
WantedBy=multi-user.targetApart from some infrastructural settings like the number of file descriptors and restart policies, the service file basically runs a single command. It refers to the starter program arangodb, which needs a few options to find all the secret files we have set up, these should be self-explanatory from what we have written above.
The network fabric of the cluster basically comes together since every instance of the starter gets told its own address (with the --starter.address option), as well as a list of all the participating starters (with the --starter.join option). We are achieving this by setting the actual server hostname in the line with Environment=SERVER=.... Then we can refer to this environment variable with the syntax ${SERVER} further down in the service file. This means that the above file has to be edited in just a single place for each individual machine, namely, you have to set the SERVER name.
Provided the above file has been given the name arango.service on your local machine, then you can deploy the service with the following commands on local machine:
scp arango.service root@sync-dc1-node01:/etc/systemd/system/arango.service
scp arango.service root@sync-dc1-node02:/etc/systemd/system/arango.service
scp arango.service root@sync-dc1-node03:/etc/systemd/system/arango.serviceYou then have to edit this file and adjust the server name, as described above. Then you launch the service with the following commands on each node in the cluster:
systemctl daemon-reload
systemctl start arangoYou can check the status of the service with:
systemctl status arangoOr investigate the live log file by running:
journalctl -flu arangoPlease note that all the data for the cluster resides in subdirectories of /arangodb/data. Every instance on each machine has a subdirectory there that contains its port in the directory name. You can find further log files in these subdirectories.
You should now be able to point your browser to port 8529 on any of the nodes. Before that, we recommend that you tell your browser to trust the tls-ca.crt certificate for server authentication. Since the public server keys are signed by the private CA key, your browser can then successfully prevent any man-in-the-middle attack.
An important step is now to change the root password, which will be empty in the beginning. You can use the UI for this.
We now set up the second cluster in a completely similar way. We simply show the commands used for that as they differ in some detail related to node names and such:
Extract the downloaded binary in its target location:
On your local machine run:
scp arangodb3e-linux-3.8.0.tar.gz root@sync-dc2-node01:/tmp
scp arangodb3e-linux-3.8.0.tar.gz root@sync-dc2-node02:/tmp
scp arangodb3e-linux-3.8.0.tar.gz root@sync-dc2-node03:/tmpThen on each machine of the second cluster:
mkdir -p /arangodb/data
cd /arangodb
tar xzvf /tmp/arangodb3e-linux-3.8.0.tar.gz
export PATH=/arangodb/arangodb3e-linux-3.8.0/bin:$PATHCreate a shared secret for the second cluster
Perform these commands on your local machine:
arangodb create jwt-secret --secret secretdc2.jwt
scp secretdc2.jwt root@sync-dc2-node01:/arangodb/data
scp secretdc2.jwt root@sync-dc2-node02:/arangodb/data
scp secretdc2.jwt root@sync-dc2-node03:/arangodb/dataWarning: Keep the file secretdc2.jwt in a safe place, possession of the file grants unrestricted superuser access to the database.
Create a CA and server keys, Then deploy them:
Note that we are using the same pair of CA keys for the TLS setup here as before during the preparation of the first cluster, so we rely on the files tls-ca.key and tls-ca.crt on your local machine. Perform these commands:
arangodb create tls keyfile --host localhost --host 127.0.0.1 --host sync-dc2-node01 --host sync-dc2-node02 --host sync-dc2-node03 --keyfile sync-dc2-nodes.keyfile
scp sync-dc2-nodes.keyfile root@sync-dc2-node01:/arangodb/data
scp sync-dc2-nodes.keyfile root@sync-dc2-node02:/arangodb/data
scp sync-dc2-nodes.keyfile root@sync-dc2-node03:/arangodb/dataKeep the file sync-dc2-nodes.keyfile secure, since possession of it allows one to listen in to the communication with your servers.
Create an encryption key for encryption at rest
This is totally parallel to what we did for the first cluster. On your local machine run:
dd if=/dev/random of=sync-dc2-nodes.encryption bs=1 count=32
chmod 600 sync-dc2-nodes.encryption
scp sync-dc2-nodes.encryption root@sync-dc2-node01:/arangodb/data
scp sync-dc2-nodes.encryption root@sync-dc2-node02:/arangodb/data
scp sync-dc2-nodes.encryption root@sync-dc2-node03:/arangodb/dataKeep the encryption key secret, because possession allows one to open a database at rest, if one can get hold of the database files in the filesystem.
Create a shared secret to use with ArangoSync:
Run the following on your local machine:
arangodb create jwt-secret --secret syncsecretdc2.jwt
scp syncsecretdc2.jwt root@sync-dc2-node01:/arangodb/data
scp syncsecretdc2.jwt root@sync-dc2-node02:/arangodb/data
scp syncsecretdc2.jwt root@sync-dc2-node03:/arangodb/dataKeep the file syncsecretdc2.jwt a secret, since its possession allows it to interfere with the ArangoSync system.
Create a TLS encryption setup for ArangoSync:
Again, we proceed exactly as for the first cluster. Do this on your local machine:
arangodb create tls keyfile --host localhost --host 127.0.0.1 --host sync-dc2-node01 --host sync-dc2-node02 --host sync-dc2-node03 --keyfile synctlsdc2.keyfile
scp synctlsdc2.keyfile root@sync-dc2-node01:/arangodb/data
scp synctlsdc2.keyfile root@sync-dc2-node02:/arangodb/data
scp synctlsdc2.keyfile root@sync-dc2-node03:/arangodb/dataAs usual, keep the file synctlsdc2.keyfile secure, since its possession allows you to listen to the encrypted traffic with the ArangoSync system.
Set up client authentication setup for ArangoSync:
Note that for simplicity, we use the same client authority CA for DC B as we did for DC A. This is not necessary but avoids a bit of confusion. On your local machine run:
arangodb create client-auth keyfile --host localhost --host 127.0.0.1 --host sync-dc2-node01 --host sync-dc2-node02 --host sync-dc2-node03 --keyfile client-auth-dc2.keyfile
scp client-auth-ca.crt root@sync-dc2-node01:/arangodb/data
scp client-auth-ca.crt root@sync-dc2-node02:/arangodb/data
scp client-auth-ca.crt root@sync-dc2-node03:/arangodb/dataMake sure to keep the file client-auth-ca.key and client--auth-par.keyfile secretly stored outside of the cluster.
Now, we’re ready to launch the second cluster:
We use a very similar service file like we did with the first cluster:
[Unit]
Description=Run the ArangoDB Starter
After=network.target
[Service]
# system limits
LimitNOFILE=131072
LimitNPROC=131072
TasksMax=131072
Restart=on-failure
KillMode=process
Environment=SERVER=sync-dc2-node01
ExecStart=/arangodb/arangodb3e-linux-3.8.0/bin/arangodb \
--starter.data-dir=/arangodb/data \
--starter.address=${SERVER} \
--starter.join=sync-dc2-node01,sync-dc2-node02,sync-dc2-node03 \
--auth.jwt-secret=/arangodb/data/secretdc2.jwt \
--ssl.keyfile=/arangodb/data/sync-dc2-nodes.keyfile \
--rocksdb.encryption-keyfile=/arangodb/data/sync-dc2-nodes.encryption \
--starter.sync=true \
--sync.start-master=true \
--sync.start-worker=true \
--sync.master.jwt-secret=/arangodb/data/syncsecretdc2.jwt \
--sync.server.keyfile=/arangodb/data/synctlsdc2.keyfile \
--sync.server.client-cafile=/arangodb/data/client-auth-ca.crt \
TimeoutStopSec=60
[Install]
WantedBy=multi-user.targetProvided the above file is named arango-dc2.service on your local machine, then you can deploy the service with the following commands on your local machine:
scp arango-dc2.service
root@sync-dc2-node01:/etc/systemd/system/arango.service
scp arango-dc2.service root@sync-dc2-node02:/etc/systemd/system/arango.service
scp arango-dc2.service root@sync-dc2-node03:/etc/systemd/system/arango.serviceThen, edit this file and adjust the server name, as described above. Then you need to launch the service with these commands on each machine in the cluster:
systemctl daemon-reload
systemctl start arangoYou can query the status of the service with:
systemctl status arangoOr investigate the live log file by running:
journalctl -flu arangoNote that all the data for the cluster resides in subdirectories of /arangodb/data. Every instance on each machine has a subdirectory there which contains its port in the directory name. You can find further log files in these subdirectories.
You should now be able to point your browser to port 8529 on any of the nodes and connect to the ArangoDB UI.
Don’t forget to change the root password for your installation. This can be easily done via the ArangoDB UI.
Enable ArangoSync synchronization and start it by using the CLI:
ArangoSync is controlled via its CLI, this CLI will be installed together with ArangoDB so there's no need to separately search for it in order to download and install it.
To configure DC to DC synchronisation from DC A to DC B, you now have to run this command on your local machine:
arangosync configure sync --master.endpoint=https://sync-dc2-node01:8532 --master.cacert=tls-ca.crt --auth.user=root --auth.password=<password> --source.endpoint=https://sync-dc1-node01:8532 --source.cacert=tls-ca.crt --master.keyfile=client-auth.keyfileIf you want (or need) to check if replication is running, you can run the following two commands:
arangosync get status -v --master.endpoint=https://sync-dc1-node01:8532 --master.cacert=tls-ca.crt --auth.user=root --auth.password=<password>
arangosync get status -v --master.endpoint=https://sync-dc2-node01:8532 --master.cacert=tls-ca.crt --auth.user=root --auth.password=<password>Get detailed information on running synchronization tasks:
arangosync get tasks -v --master.endpoint=https://sync-dc1-node01:8532 --master.cacert=tls-ca.crt --auth.user=root --auth.password=<password>
arangosync get tasks -v --master.endpoint=https://sync-dc2-node01:8532 --master.cacert=tls-ca.crt --auth.user=root --auth.password=<password>Momentarily stop the synchronization process:
arangosync stop sync --master.endpoint=https://sync-dc2-node01:8532 --master.cacert=tls-ca.crt --auth.user=root --auth.password=<password> --ensure-in-sync=trueThis will briefly stop writes to DC A until both clusters are in perfect sync. It will then stop synchronization and switch DC B back to read/write mode. You can use the switch --ensure-in-sync=false if you do not want to wait for synchronization to be ensured.
Abort synchronization:
Losing connectivity between the two separate locations because of a network or other outage will mean you need to stop synchronization entirely with the following command:
arangosync abort sync --master.endpoint=https://sync-dc2-node01:8532 --master.cacert=tls-ca.crt --auth.user=root --auth.password=<password>This is the command to abort the synchronization on the target side (DC B). If there is no connectivity between the clusters, then this will naturally not abort the outgoing synchronization in DC A. Therefore, it is possible that you have to additionally send a corresponding command to the syncmaster in DC A, too.
It has a slightly different syntax:
arangosync abort outgoing sync --master.endpoint=https://sync-dc1-node01:8532 --master.cacert=tls-ca.crt --auth.user=root --auth.password=<password> --target <id>The <id> will need to be replaced by the ID of the cluster in DC B. You can retrieve this ID via the arangosync get status output of DC A. There you can also tell if this is necessary, if you see an outgoing synchronization which does not have a corresponding incoming synchronization in the other DC, the ArangoSync abort outgoing sync command is needed.
Restart synchronization in the opposite direction:
arangosync configure sync --master.endpoint=https://sync-dc1-node01:8532 --master.cacert=tls-ca.crt --source.cacert=tls-ca.crt --master.keyfile=client-auth.keyfile --auth.user=root --auth.password=<password> --source.endpoint=https://sync-dc2-node01:8532More details on the ArangoSync CLI and its options can be found in our documentation at:
https://www.arangodb.com/docs/stable/administration-dc2-dc.html
Concluding words
As I wrote at the very beginning of this blog post, we have thought long and hard about an ideal topic and we’re very excited that a lot of our users want to use ArangoSearch either to test or in production. We truly hope that this is a great start for those looking into a rock-solid replicated database environment and wish you serious heaps of fun rolling it out and check out the benefits!
Continue Reading
A Comprehensive Case-Study of GraphSage using PyTorchGeometric and Open-Graph-Benchmark
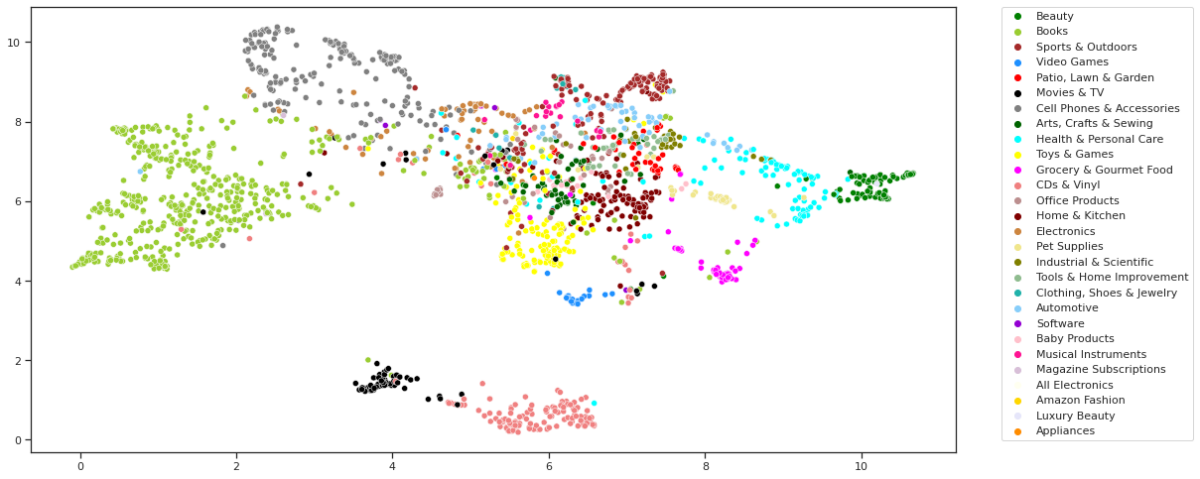
A Comprehensive Case-Study of GraphSage using PyTorchGeometric and Open-Graph-Benchmark
Estimated reading time: 15 minute
This blog post provides a comprehensive study on the theoretical and practical understanding of GraphSage, this notebook will cover:
- What is GraphSage
- Neighbourhood Sampling
- Getting Hands-on Experience with GraphSage and PyTorch Geometric Library
- Open-Graph-Benchmark’s Amazon Product Recommendation Dataset
- Creating and Saving a model
- Generating Graph Embeddings Visualizations and Observations

Community Notebook Challenge
Calling all Community Members! 🥑
Today we are excited to announce our Community Notebook Challenge.
What is our Notebook Challenge you ask? Well, this blog post is going to catch you up to speed and get you excited to participate and have the chance to win the grand prize: a pair of custom Apple Airpod Pros.
(more…)Introducing ArangoDB 3.8 – Graph Analytics at Scale
Estimated reading time: 5 minutes
We are proud to announce the GA release of ArangoDB 3.8!
With this release, we improve many analytics use cases we have been seeing – both from our customers and open-source users – with the addition of new features such as AQL window operations, graph and Geo analytics, as well as new ArangoSearch functionality.

If you want to get your hands on ArangoDB 3.8, you can either download the Community or Enterprise Edition, pull our Docker images, or start a free trial of our managed service ArangoGraph.
As with any release, ArangoDB 3.8 comes with many improvements, bug fixes, and features. Feel free to browse through the complete feature list in the release notes to appreciate all the work which has gone into this release.
In this blog post, we want to focus on some of the highlights including AQL Window Operations, Weighted Graph Traversals, Pipeline Analyzer and Geo Support in ArangoSearch.
AQL Window Operations
The WINDOW keyword can be used for aggregations over related rows, usually preceding and / or following rows.
The WINDOW operation performs a COLLECT AGGREGATE-like operation on a set of query rows. However, whereas a COLLECT operation groups multiple query rows into a single result group, a WINDOW operation produces a result for each query row:
- The row for which function evaluation occurs is called the current row
- The query rows related to the current row over which function evaluation occurs comprise the window frame for the current row
There are two syntax variants for WINDOW operations:
- Row-based (evaluated across adjacent documents)
- Range-based (evaluated across value or duration range)

Weighted Graph Traversals
Graph traversals in ArangoDB 3.8 support a new traversal type, "weighted", which enumerates paths by increasing weights.
The cost of an edge can be read from an attribute which can be specified with the weightAttribute option.
FOR x, v, p IN 0..10 OUTBOUND "places/York" GRAPH "kShortestPathsGraph"
OPTIONS {
order: "weighted",
weightAttribute: "travelTime",
uniqueVertices: "path"
}As the previous traversal option bfs was deprecated, the new preferred way to start a breadth-first search from now on is with order: "bfs". The default remains depth-first search if no order is specified, but can also be explicitly requested with order: "dfs".
ArangoSearch Pipeline & AQL Analyzers
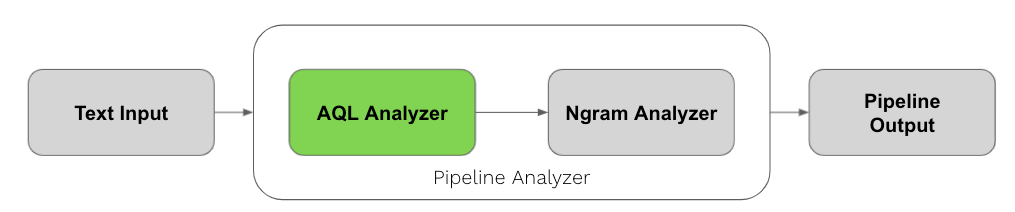
ArangoSearch added a new Analyzer type, "pipeline", for chaining effects of multiple Analyzers into one. This allows for example to combine text normalization for a case insensitive search with n-gram tokenization, or to split text at multiple delimiting characters followed by stemming.
Furthermore, the new Analyzer type "aql"is capable of running an AQL query (with some restrictions) to perform data manipulation/filtering. For example, a user can define a soundex analyzer for phonetically similar term search:
arangosh> var a = analyzers.save("soundex", "aql", { queryString: "RETURN SOUNDEX(@param)" }, ["frequency", "norm", "position"]);Note that the query must not access the storage engine. This means no FOR loops over collections or Views, no use of the DOCUMENT() function and no graph traversals.
Enhanced Geo support in ArangoSearch
While AQL has supported Geo indexing and functions for a long time, ArangoDB 3.8 adds Geo support also to ArangoSearch with the GeoJSON and GeoPoint analyzer and respective ArangoSearch Geo functions:
- Geo_Contains()
- Geo_Distance()
- Geo_In_Range()
- Geo_Intersects()
NB: Check out the community ArangoBnB project to learn more about Geo capabilities in ArangoSearch.
Improved Replication Protocol
For collections created with ArangoDB 3.8, a new internal data format is used that allows for a very fast synchronization of differences between the leader and a follower that is trying to reconnect.
The new format used in 3.8 is based on Merkle trees, making it more efficient to pin-point the data differences between the leader and a follower that is trying to reconnect.
The algorithmic complexity of the new protocol is determined by the amount of differences between the leader and follower shard data, meaning that if there are no or very few differences, the getting-in-sync protocol will run very fast. In previous versions of ArangoDB, the complexity of the protocol was determined by the number of documents in the shard, and the protocol required a scan over all documents in the shard on both the leader and the follower to find the differences.
The new protocol is used automatically for all collections/shards created with ArangoDB 3.8. Collections/shards created with earlier versions will use the old protocol, which is still fully supported. Note that such “old” collections will only benefit from the new protocol if the collections are logically dumped and recreated/restored using arangodump and arangorestore.
Other notable features
- UI and Visualizer Improvements
- Default per-query and optional global memory limits
- Metrics 2.0 version and user specific Grafana dashboards
- Arangodump improvements
- JavaScript security
- AQL bit functions
- Sorting performance improvements
- Agency Memory consumption
- Hardware acceleration for Encryption
Upgrade
Upgrading to ArangoDB 3.8 can be performed with zero downtime following the upgrade instructions for your respective deployment option. Please note our recent update advisory and update either to a newer 3.6/3.7 version or 3.8 if you are running an affected version.
ArangoGraph
The easiest way to give ArangoDB 3.8 a spin is ArangoGraph, ArangoDB’s managed service in the cloud.
Feedback
Feel free to provide any feedback either via our Slack channel or mailing list.
Special Edition Lunch Session
Join Simran Spiller on August 4th for a special Graph and Beyond Lunch Session #15.5 - Aggregating Time-Series Data with AQL.
The new WINDOW operation added to AQL in ArangoDB 3.8 allows you to compute running totals, rolling averages, and other statistical properties of your sensor, log, and other data. You can aggregate adjacent documents (or rows if you will), as well as documents in value or duration ranges with a sliding window.
In this lunch and learn session, we will take a look at the two syntax variants of the WINDOW operation and go over a few examples queries with visual explanations.
Hear More from the Author
Continue Reading
Introducing Developer Deployments on ArangoDB ArangoGraph
Entity Resolution in ArangoDB
Estimated reading time: 8 minutes
This post will dive into the world of Entity Resolution in ArangoDB. This is a companion piece for our Lunch and Learn session, Graph & Beyond Lunch Break #15: Entity Resolution.
In this article we will:
- give a brief background in Entity Resolution (ER)
- discuss some use-cases for ER
- discuss some techniques for performing ER in ArangoDB
Inside the Avocado Grove: From Canada to Germany and the Digital Marketing of Avocados
Estimated reading time: 8 minutes
My name is Laura, and I am responsible for digital marketing here at ArangoDB.
In the following post, I will dive into my own experience working at ArangoDB and how I ended up from Northern Ontario, Canada to work in Germany at a native multi-model graph database company. Are you interested in learning more about working abroad, working remotely, or diving into a new industry? This post covers all of the above topics.
(more…)Word Embeddings in ArangoDB
Estimated reading time: 12 minute
This post will dive into the world of Natural Language Processing by using word embeddings to search movie descriptions in ArangoDB.
In this post we:
- Discuss the background of word embeddings
- Introduce the current state-of-the-art models for embedding text
- Apply a model to produce embeddings of movie descriptions in an IMDb dataset
- Perform similarity search in ArangoDB using these embeddings
- Show you how to query the movie description embeddings in ArangoDB with custom search terms
Introducing Developer Deployments on ArangoDB ArangoGraph
Estimated reading time: 4 minutes
Today we’re announcing the introduction of Developer deployments as a beta feature on the Oasis platform.
In this blog post, we’ll tell you what Developer deployments are, what you can do with them, what you should not do with them, and how to get started.
What are Developer deployments?
Since we launched Oasis, a deployment on Oasis has always been a highly available ArangoDB cluster. That is great for high availability, and it allows you to scale your deployment to incredibly large sets of data.
Many customers have told us that they would like something a bit smaller that can be used by an individual developer, or better yet, let every developer have their own deployment.
That request is exactly what we are answering with the introduction of Developer deployments.
A Developer deployment consists of only a single server on a single node.
With that configuration, there is obviously no high availability, and scaling is limited to vertical scaling of that single server.
For those reasons, Developer deployments are not suitable for any kind of production environment, and because of that, Developer deployments are excluded from audit logs.
Support is given for Developer deployments on a best effort basis. It is not possible to buy an additional support plan with a Developer deployment.
All other features, like backups, full encryption, and Foxx, are fully available.
What can you do with a Developer deployment?
Developer deployments are ideal when you want to experiment with ArangoDB, or are just learning its features.
They are also ideal for (small scale) analytics experiments. You can quickly load your data into them, configure your graphs and perform your analysis.
The lack of high availability is usually not a problem for such experiments.
Of course, you can also give a single Developer deployment to all of your developers to develop an application against. When you do so, you have to keep in mind that there are small differences between a single instance of ArangoDB and a cluster.
Within Oasis, we have reduced these changes by requiring the use of the WITH statement in exactly the same way that a cluster deployment requires that keyword (from ArangoDB version 3.7.12 and higher).
How are Developer deployments priced?
A Developer deployment launched in AWS Ohio is available for as little as $ 0.058 per hour or $42.2 per month. The same deployment with General CPU is available for $ 0.068 per hour.
Similar to our OneShard and Sharded deployments, network traffic and backup storage is charged separately.
For more details on pricing, please log in to the Oasis dashboard and visit the Pricing page.
What not do with Developer deployments
As mentioned before, Developer deployments are not highly available and can be restarted at any time. For that reason, you should not use them for any kind of production environment.
Since we strongly believe that a staging environment should reflect the production environment as much as possible, you should also not use a Developer deployment for a staging environment.
How to get started with Developer deployments
To create a Developer deployment on Oasis, log in to your ArangoDB Oasis account on cloud.arangodb.com.
Then go to your project and click on New Deployment.

Enter all the normal fields such as the name of your deployment and select a cloud provider & region.
Then click on the Developer (beta) button to choose the Developer model.
![]()
Select the size of your deployment and click on Create.

Your Developer deployment will now bootstrap.
Once that has finished, you’ll receive an email and can start to use your deployment.
Hear More from the Author
OCB: Challenges in Building Multi-Cloud-Provider Platform With Kubernetes
Getting Started with ArangoDB Oasis
Continue Reading
ArangoML Part 1: Where Graphs and Machine Learning Meet
A story of a memory leak in GO: How to properly use time.After()
Get the latest tutorials,
blog posts and news: