 Skip to content
Skip to content Static binaries for a C++ application
ArangoDB is a multi-model database written in C++. It is a sizable application with an executable size of 38MB (stripped) and quite some library dependencies. We provide binary packages for Linux, Windows and MacOS, and for Linux we cover all major distributions and their different versions, which makes our build and delivery pipeline extremely cluttered and awkward. At the beginning of this story, we needed approximately 12 hours just to build and publish a release, if everything goes well. This is the beginning of a tale to attack this problem. Read more
Win your free ticket and join ArangoDB @ JontheBeach 2018

We are thrilled to be attending one of Europe’s greatest events – JontheBeach (JOTB), an international rendezvous for developers and DevOps around Big Data technologies. No product talks just deep-tech topics presented by hand-picked speakers from Google, Apache Spark, RedHat, Stripe, Microsoft and many more. Read more
Welcome to the ArangoDB family, Ted Dunning!
We are absolutely thrilled to announce that one of the brightest and most respected minds in open-source software joins ArangoDBs Advisory Council. Hi, Ted and welcome to the ArangoDB family!

For those who don’t know Ted Dunning yet, maybe a quick introduction and the reason why the whole team is so amazed that he supports the project. Ted Dunning is Chief Application Architect at MapR, holds a PhD in computer science and is committer as well as PMC member of the Apache Mahout, Zookeeper and Drill projects. Besides his 25 patents, and even more pending, he mentors multiple well-known Apache projects like Storm, Flink, or DataFu with his broad experiences across industries and technologies. Ted contributes so much to the open-source world and we feel blessed to have him on board at ArangoDB. Read more
ArangoDB Easter Egg Hunt: Join the Fun and Discover Surprises!

While working hard on the next release and hacking away new interesting things to include into our favourite database, we decided to take a short break to have some fun just in time for Easter. All teams gathered together to do some Easter eggs coloring, chocolate-eating and fun-having 🙂
We’ve colored a lot of eggs in our favourite colors – green and brown, and hid them all around our office and beyond. Now, here is a little challenge for you to help us find them. Read more
ArangoDB Java Driver: Load Balancing for Performance
The newest release 4.3.2 of the official ArangoDB Java driver comes with load balancing for cluster setups and advanced fallback mechanics.
Load balancing strategies
Round robin
There are two different strategies for load balancing that the Java driver provides. The first and most common strategy is the round robin way. Round robin does, what the name already assumes, a round robin load balancing where a list of known coordinators in the cluster is iterated through. Each database operation uses a different coordinator than the one before. Read more
ArangoDB Named Best Free Graph Database by G2 Crowd Users
ArangoDB named by G2 Crowd users as the most popular graph database used today.
ArangoDB has been identified as the highest rated graph database, based on its high levels of customer satisfaction and likeliness to recommend ratings from real G2 Crowd users.
ArangoDB received a near perfect 4.9 out of 5 star average for user satisfaction for its free platform across its 24 user reviews. ArangoDB users point to the database’s query language, availability and storage as the three most liked features of the product. Read more
ArangoDB | Introduction to Fuerte: ArangoDB C++ Driver
In this post, we will introduce you to our new ArangoDB C++ diver fuerte. fuerte allows you to communicate via HTTP and VST with ArangoDB instances. You will learn how to create collections, insert documents, retrieve documents, write AQL Queries and how to use the asynchronous API of the driver.
Requirements (Running the sample)
Please download and inspect the sample described in this post. The sample consists of a C++ – Example Source Code – File and a CMakeLists.txt. You need to install the fuerte diver, which can be found on github, into your system before compiling the sample. Please follow the instructions provided in the drivers README.md. Read More
Performance analysis with pyArango: Part III Measuring possible capacity with usage Scenarios
Auto-Generate GraphQL for ArangoDB
Currently, querying ArangoDB with GraphQL requires building a GraphQL.js schema. This is tedious and the resulting JavaScript schema file can be long and bulky. Here we will demonstrate a short proof of concept that reduces the user related part to only defining the GraphQL IDL file and simple AQL queries.
The Apollo GraphQL project built a library that takes a GraphQL IDL and resolver functions to build a GraphQL.js schema. Resolve functions are called by GraphQL to get the actual data from the database. I modified the library in the way that before the resolvers are added, I read the IDL AST and create resolver functions.
To simplify things and to not depend on special "magic", let's introduce the directive `@aql`. With this directive, it's possible to write an AQL query that gets the needed data. With the bind parameter `@current` it is possible to access the current parent object to do JOINs or related operations.
Interested in trying out ArangoDB? Fire up your database in just a few clicks with ArangoDB ArangoGraph: the Cloud Service for ArangoDB. Start your free 14-day trial here.
A GraphQL IDL
type BlogEntry {
_key: String!
authorKey: String!
author: Author @aql(exec: "FOR author IN Author FILTER author._key == @current.authorKey RETURN author")
}
type Author {
_key: String!
name: String
}
type Query {
blogEntry(_key: String!): BlogEntry
}This IDL describes a `BlogEntry` and an `Author` object. The `BlogEntry` holds an `Author` object which is fetched via the AQL query in the directive `@aql`. The type Query defines a query that fetches one `BlogEntry`.
Now let's have a look at a GraphQL query:
{
blogEntry(_key: "1") {
_key
authorKey
author {
name
}
}
}This query fetches the `BlogEntry` with `_key` "1". The generated AQL query is:
FOR doc IN BlogEntry FILTER doc._key == '1' RETURN docAnd with the fetched `BlogEntry` document the corresponding `Author` is fetched via the AQL query defined in the directive.
The result will approximately look like this:
{
"data" : {
"blogEntry" : {
"_key" : "1",
"authorKey" : "2",
"author" : {
"name" : "Author Name"
}
}
}
}As a conclusion of this short demo, we can claim that with the usage of GraphQLs IDL, it is possible to reduce effort on the users' side to query ArangoDB with GraphQL. For simple GraphQL queries and IDLs it's possible to automatically generate resolvers to fetch the necessary data.
The effort resulted in an npm package is called graphql-aql-generator.
ArangoDB Foxx example
Now let’s have a look at the same example, but with using ArangoDB javascript framework - Foxx. To do so, we have to follow the simple steps listed below:
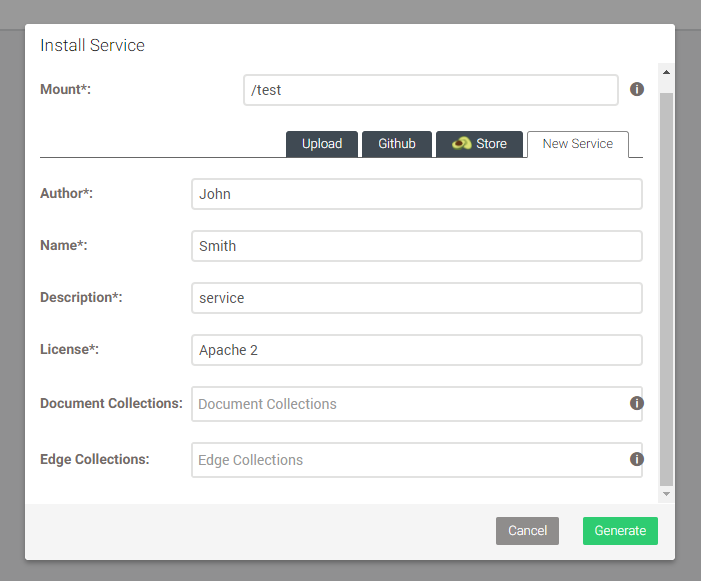
- Open the ArangoDB web interface and navigate to `SERVICES`.
- Then click `Add Service`. Select `New Service` and fill out all fields with `*`.
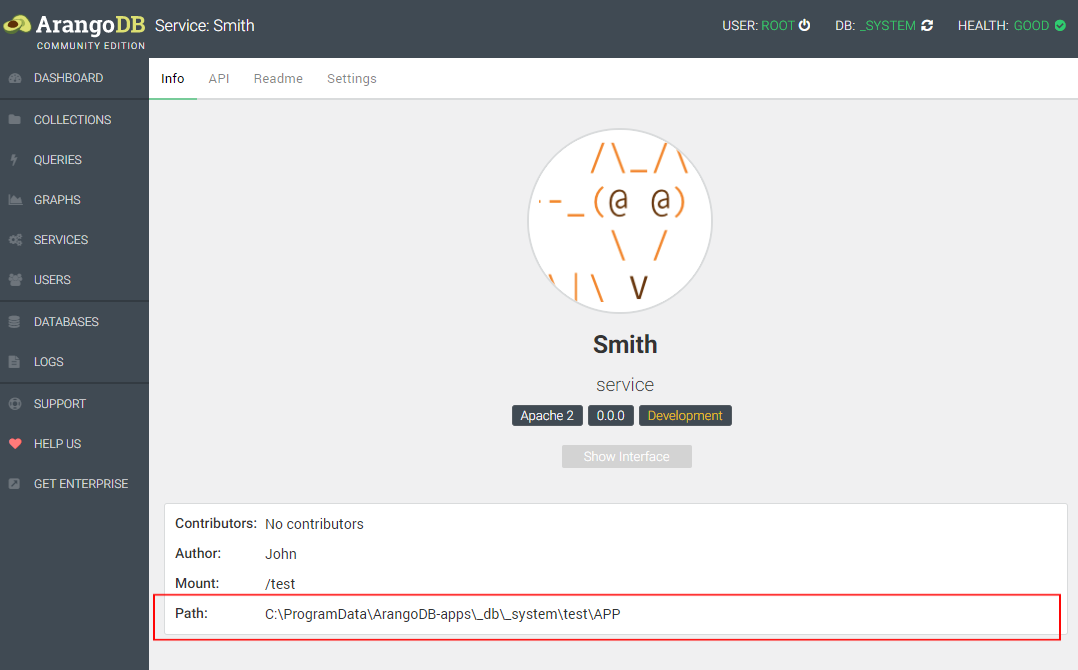
Important is the `Mount` field. I will use `/test`. Then Generate. - Click on the service to open its settings. Click `Settings` and then go to `Set Development` to enable the development mode.
- Then click `Info` and open the path at `Path:`.
Now we have to install the npm package:
npm install --save graphql-aql-generatorWe also need the collections `Author` and `BlogEntry`. And the following documents:
- `Author` collection:
{
"_key":"2"
"name": "Author Name"
}- `BlogEntry` collection:
{
"_key":"1"
"authorKey": "2"
}Foxx has a built-in graphql router that we can use to serve GraphQL queries. We assemble a new route called `/graphql` that serves the incoming GraphQL queries. With `graphiql: true` we enable the GraphiQL explorer so we can test-drive our queries.
const createGraphQLRouter = require('@arangodb/foxx/graphql');
const generator = require('graphql-aql-generator');
const typeDefs = [`...`]
const schema = generator(typeDefs);
router.use('/graphql', createGraphQLRouter({
schema: schema,
graphiql: true,
graphql: require('graphql-sync')
}));Open `127.0.0.1:8529/test/graphql` and the GraphiQL explorer is loaded so we can execute a query to fetch a `BlogEntry` with an `Author`.
{
blogEntry(_key: "1") {
_key
authorKey
author {
name
}
}
}
```
The result is:
```
{
"data": {
"blogEntry": {
"_key": "1",
"authorKey": "2",
"author": {
"name": "Author Name"
}
}
}
}For the sake of completeness, here is the full Foxx example that works by copy & paste. Do not forget to
`npm install graphql-aql-generator` and create the collections and documents.
// main.js code
'use strict';
const createRouter = require('@arangodb/foxx/router');
const router = createRouter();
module.context.use(router);
const createGraphQLRouter = require('@arangodb/foxx/graphql');
const generator = require('graphql-aql-generator');
const typeDefs = [`
type BlogEntry {
_key: String!
authorKey: String!
author: Author @aql(exec: "FOR author in Author filter author._key == @current.authorKey return author")
}
type Author {
_key: String!
name: String
}
type Query {
blogEntry(_key: String!): BlogEntry
}
`]
const schema = generator(typeDefs);
router.use('/graphql', createGraphQLRouter({
schema: schema,
graphiql: true,
graphql: require('graphql-sync')
}));Would be great to hear your thoughts, feedback, questions, and comments in our Slack Community channel or via a contact us form.
ArangoDB | PyArango Performance Analysis – Transaction Inspection
Following the previous blog post on performance analysis with pyArango, where we had a look at graphing using statsd for simple queries, we will now dig deeper into inspecting transactions. At first, we split the initialization code and the test code.
Initialisation code
We load the collection with simple documents. We create an index on one of the two attributes: Read more